Little Endian
A ordem de bytes usada para armazenar inteiros
-
 Greg Walker
Greg Walker - Atualizado em
O termo little-endian se refere à ordem dos bytes ao armazenar inteiros em um computador. É quando o byte menos significativo vem primeiro ou, mais simplesmente, quando os bytes aparecem ao contrário.
Quase todos os inteiros nos dados brutos do bitcoin estão em ordem little-endian, então vale a pena se acostumar.
Exemplo
O que é little-endian?
Digamos que estamos definindo o valor de uma saída de transação como 12345678 satoshis.
Agora, o campo valor tem 8 bytes de tamanho. Então, se convertermos esse valor para bytes hexadecimais, ele fica assim:
00 00 00 00 00 bc 61 4e
Essa ordem de bytes é chamada de big-endian.
Obviamente não esgotamos esse campo, já que o maior inteiro que esse campo de 8 bytes pode conter é 0xffffffffffffffff (ou 18446744073709551615). Isso é óbvio porque há muitos zeros à esquerda, e nós, humanos, esperamos ver os maiores números à esquerda.
Porém, os computadores (e o bitcoin) gostam de ler esses bytes pela outra direção:
4e 61 bc 00 00 00 00 00
Essa ordem de bytes é chamada de little-endian.
Temos exatamente os mesmos bytes, mas em ordem inversa. Então, em vez de ler os menores bytes da direita para a esquerda, agora os lemos da esquerda para a direita.
Ordens de Bytes

Como mencionado, há duas formas diferentes de ordenar bytes ao armazenar inteiros em um computador:
- Big Endian
- Little Endian
Alguns computadores usam arquitetura big-endian, e outros usam little-endian.
1. Big Endian
(Raramente usado no Bitcoin)
É o formato mais "legível para humanos". O byte contendo o maior número vem primeiro:
00 00 00 00 00 bc 61 4e
Ou, mais tecnicamente, é quando o byte mais significativo é armazenado no menor endereço de memória de um bloco de bytes. Por exemplo:
┌────────────────┬──────────┐
│ Endereço de │ Conteúdo │
│ Memória │ │
├────────────────┼──────────┤
│ 100 │ 0x00 │
│ 101 │ 0x00 │
│ 102 │ 0x00 │
│ 103 │ 0x00 │
│ 104 │ 0x00 │
│ 105 │ 0xbc │
│ 106 │ 0x61 │
│ 107 │ 0x4e │
└────────────────┴──────────┘
2. Little Endian
(Comumente usado no Bitcoin)
É o formato mais "legível para computadores". O byte contendo o menor número vem primeiro:
4e 61 bc 00 00 00 00 00
Ou, mais tecnicamente, é quando o byte mais significativo é armazenado no maior endereço de memória de um bloco de bytes. Por exemplo:
┌────────────────┬──────────┐
│ Endereço de │ Conteúdo │
│ Memória │ │
├────────────────┼──────────┤
│ 100 │ 0x4e │
│ 101 │ 0x61 │
│ 102 │ 0xbc │
│ 103 │ 0x00 │
│ 104 │ 0x00 │
│ 105 │ 0x00 │
│ 106 │ 0x00 │
│ 107 │ 0x00 │
└────────────────┴──────────┘
Como você deve imaginar, o Satoshi estava trabalhando em um computador little-endian ao programar o bitcoin.
Terminologia
Por que se chama "little-endian" e "big-endian"?
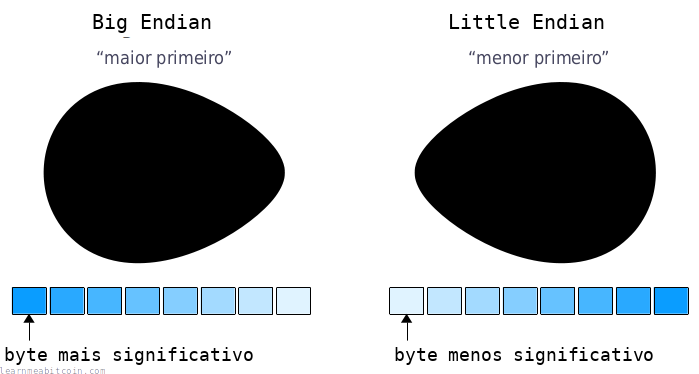
Por causa de ovos, basicamente.
Os termos "little-endian" e "big-endian" têm origem no livro As Viagens de Gulliver (1726). Há uma parte que se refere a dois grupos diferentes de pessoas: um que quebra ovos pela "ponta pequena" (little end) e outro que quebra pela "ponta grande" (big end).
Esses termos "little end" e "big end" foram então adotados para descrever as duas formas diferentes de ordenar bytes em um computador.
Uso
Quando usamos little-endian no bitcoin?
Você encontrará campos little-endian no bitcoin sempre que trabalhar com inteiros dentro de mensagens da rede. Os lugares mais comuns são os dados brutos de transação e os cabeçalhos de bloco brutos.
Dados de Transação
Aqui está uma transação bruta. Eu a dividi e destaquei os campos little-endian em verde.
02000000 <- versão (little-endian)
01 <- contagem de entradas
79fe743502ff8cd181121572fececac3feee5ef3034edfb3ccd2bfaa24537dae <- txid
01000000 <- vout (little-endian)
6a 473044022...915 <- scriptsig
fdffffff <- sequence (little-endian)
01 <- contagem de saídas
2a5f020000000000 <- valor da saída (little-endian)
19 76a914a9970b7ed051822ea52a088b9c628eb158dd57e588ac <- scriptpubkey
ff30a00 <- locktime (little-endian)
Por exemplo, o vout é um campo little-endian de 4 bytes e, nesta transação, se refere a uma saída anterior de número 1. Se esse campo fosse big-endian, seria 00000001, mas, por ser little-endian, os bytes ficam em ordem inversa: 01000000.
Cabeçalho de Bloco
Aqui está um cabeçalho de bloco bruto.
00000020 <- versão (little-endian)
b91fd2b09d4a8238ad4c814e4fa0ab9ed34bf0f75a3a00000000000000000000 <- hash do bloco anterior
330b32016c8176153071283d3e5fe87c2318b3fd41d6ca1b1a8bf12670908e38 <- raiz de merkle
daf0d861 <- tempo (little-endian)
ab980b17 <- bits (little-endian)
0e69d05c <- nonce (little-endian)
Como você pode ver, todos os campos little-endian são os que contêm algum tipo de número. Por exemplo, o tempo no cabeçalho é um campo little-endian de 4 bytes contendo um timestamp Unix. Aqui é daf0d861, que em big-endian seria 61d8f0da. Convertendo para decimal, temos 1641607386, um timestamp Unix para 08 de janeiro de 2022, 02:03:06 UTC.
Convertendo
Como converter entre big-endian e little-endian
Se você está trabalhando com strings, uma forma rápida e simples de inverter a ordem dos bytes é dividir a string em pedaços de 2 caracteres (2 caracteres hex = 1 byte) e então inverter o array.
# inverte a ordem dos bytes de uma string hex
hex = "0000000000bc614e"
little = hex.scan(/../).reverse.join
puts little #=> 4e61bc0000000000Aqui vai uma forma rápida de converter na linha de comando:
echo "0000000000bc614e" | fold -w2 | tac | tr -d '\n' #=> 4e61bc0000000000Por que o bitcoin usa little-endian?
Porque o Satoshi desenvolveu o Bitcoin em um computador com arquitetura little-endian.
Pode parecer incomum no início, mas a ordem little-endian é, na verdade, mais comum do que você imagina:
Quase todas as CPUs hoje em dia funcionam nativamente em little-endian.
Então, embora pareça ao contrário para humanos, é bem padrão para computadores.
Você normalmente não se importa com a arquitetura subjacente do seu sistema na programação do dia a dia. Mas a endianness pode se tornar relevante quando você começa a trabalhar com os bytes brutos de dados que são enviados pela rede (ex.: dados de transação).
Resumo
Little-endian é a ordem de bytes que usamos para armazenar inteiros (e outras estruturas de múltiplos bytes, como o campo bits) nos dados brutos do bitcoin, como transações e cabeçalhos de bloco.
Para o olho humano, little-endian parece ter os bytes em ordem inversa. Porém, muitos computadores modernos usam arquitetura little-endian, e o Satoshi programou a primeira versão do Bitcoin em um computador little-endian, e é por isso que usamos little-endian no Bitcoin.
Provavelmente seria mais fácil, do ponto de vista de desenvolvimento, ter tudo em big-endian, mas little-endian foi a escolha do Satoshi, então você só precisa se acostumar.
Bem-vindo à programação em bitcoin.